
Braden Hancock
AI Researcher & Investor | Partner @ Laude | Co-founder @ Snorkel AI
I am an AI researcher & investor who converted my research into a billion dollar business
with the help of an amazing team; I now help the next generation of researchers do the same.
In my 15 years of AI research experience, I have had the opportunity to
publish research at Stanford, Meta, Google, MIT, Johns Hopkins, AFRL, and BYU;
co-found Snorkel AI ($235M raised at $1.3B valuation);
lead GenAI evaluation R&D for the most downloaded open LLM family in the world (Llama);
and advise and invest in AI startups at all stages.
At every step, I've been blessed to work with amazing people!
Recent News
- Jul 2025: I started a new role as the first Research Partner at Laude Ventures and Laude Institute.
- May 2025: Snorkel AI announced $100M Series D funding at $1.3B valuation (Forbes, Business Wire, etc.).
- Apr 2025: Snorkel AI included on the 2025 Forbes America's Best Startup Employers list.
- Apr 2025: Snorkel AI included on the 2025 Forbes AI 50 list.
- Mar 2025: Snorkel AI listed at #11 on the 2025 Fast Company Top 25 Most Innovative AI Companies list, along with NVIDIA, OpenAI, Anthropic.
- Mar 2025: Snorkel included on the 2025 Newsweek Greatest Startup Workplaces list.
- Sep 2024: Llama 3.2 released with new sizes, multi-modal support, and longer context window.
- Jul 2024: Llama 3.1 released with comprehensive tech report detailing our data, training, and evaluation strategy.
- Apr 2024: Llama 3 released: the most capable openly available LLM to date.
- Feb 2024: I joined Meta to found and lead the centralized GenAI Evaluations org responsible for all things eval-related for Llama.
- Nov 2023: Snorkel AI included on the 2023 Fortune 50 AI Innovators list.
- Jul 2023: Snorkel AI included on the 2023 LinkedIn 50 Top Startups list.
- Jul 2023: Snorkel AI called out by Sundar Pichai in the Q2 Google earnings call as a partner for Generative AI.
- Jul 2023: Snorkel AI included on the 2023 NatSec100 list for top venture-funded defense and dual-use startups.
- May 2023: Delivered closing keynote at TiEcon 2023 on "GPT-You: The Next Phase of Foundation Models."
- Apr 2023: Snorkel AI included on the 2023 Forbes AI 50 list recognizing the most promising private companies in AI.
- Mar 2023: Snorkel AI included on the 2023 Forbes America's Best Startup Employers list.
- Mar 2023: Participated in NVIDIA GTC panel with Percy Liang, Ori Goshen, Jonathan Cohen, and Yejin Choi.
- Jun 2022: Snorkel AI named a 2022 Gartner Cool Vendor in AI Core Technologies.
- May 2022: Participated in an O'Reilly AI Superstream on NLP in Production.
- Apr 2022: Presented keynote at "Trustworthy AI: a Practical Roadmap for Government" event.
- Apr 2022: Presented at the Investing in Ethical AI event by BGV and the Ethical AI Governance Group.
- Mar 2022: Interviewed by Jack Cassel at NASDAQ about the state of enterprise AI.
- Mar 2022: Snorkel AI included for the second year on the Enterprise Tech 30 list—"the best enterprise tech startups"—according to top VCs.
- Mar 2022: Snorkel AI included on the inaugural Data 50 list—"the world's top data startups"—by Andreessen Zorowitz (a16z).
Experience

Laude Ventures
2025-Present
Role: Research Partner
Topics: Helping researchers turn their research into billion-dollar businesses.
Role: Research Partner
Topics: Helping researchers turn their research into billion-dollar businesses.

Laude Institute
2025-Present
Role: Research Partner
Topics: Helping researchers ship their research to impact the lives of billions.
Role: Research Partner
Topics: Helping researchers ship their research to impact the lives of billions.

Meta
2024-2025
Group: Generative AI
Role: Director of AI (founded & led Evaluation org)
Topics: Evaluation of generative AI models (e.g. Llama) and systems (Meta AI, ChatGPT, etc.)
Group: Generative AI
Role: Director of AI (founded & led Evaluation org)
Topics: Evaluation of generative AI models (e.g. Llama) and systems (Meta AI, ChatGPT, etc.)

Snorkel AI
2019-2024 (Operator), 2024-Present (Advisor)
Co-founders: Alex Ratner, Chris Ré, Paroma Varma, Henry Ehrenberg
Investors: Lightspeed, Greylock, Google Ventures, BlackRock, SV Angel, Addition, In-Q-Tel
Topics: Solving the unsexy but critical parts of AI: data and evals
Co-founders: Alex Ratner, Chris Ré, Paroma Varma, Henry Ehrenberg
Investors: Lightspeed, Greylock, Google Ventures, BlackRock, SV Angel, Addition, In-Q-Tel
Topics: Solving the unsexy but critical parts of AI: data and evals

Stanford University
2015-2019
Groups: Stanford Hazy Research, Stanford DAWN, Stanford NLP Group, Stanford StatsML
Advisor: Chris Ré, Dissertation: slides, paper
Topics: ML systems, LLMs, NLP, weak supervision, multi-task learning (MTL), training data curation
Groups: Stanford Hazy Research, Stanford DAWN, Stanford NLP Group, Stanford StatsML
Advisor: Chris Ré, Dissertation: slides, paper
Topics: ML systems, LLMs, NLP, weak supervision, multi-task learning (MTL), training data curation

Facebook
Fall 2018
Groups: Facebook AI Research (FAIR) - Paris
Mentors: Jason Weston, Antoine Bordes
Topics: Generative AI, improving chatbots with continual learning from interactions with users post-deployment
Groups: Facebook AI Research (FAIR) - Paris
Mentors: Jason Weston, Antoine Bordes
Topics: Generative AI, improving chatbots with continual learning from interactions with users post-deployment

Google
Summer 2017
Groups: Google Brain, Google Search - Mountain View
Mentors: Hongrae Lee, Cong Yu, Quoc Le
Topics: Reducing hallucinations in generative AI search results for semi-structured web content
Groups: Google Brain, Google Search - Mountain View
Mentors: Hongrae Lee, Cong Yu, Quoc Le
Topics: Reducing hallucinations in generative AI search results for semi-structured web content

MIT Lincoln Laboratory
Summers 2014-2015
Group: Computing & Analytics - Boston
Mentors: Vijay Gadepally, Jeremy Kepner
Topics: Recommender systems for DoD applications and computation on encrypted data
Group: Computing & Analytics - Boston
Mentors: Vijay Gadepally, Jeremy Kepner
Topics: Recommender systems for DoD applications and computation on encrypted data

Johns Hopkins University
Summer 2013
Group: Human Language Technology Center of Excellence - Baltimore
Mentors: Mark Dredze, Glen Coppersmith
Topics: Natural language processing (NLP), machine learning, social media mining
Group: Human Language Technology Center of Excellence - Baltimore
Mentors: Mark Dredze, Glen Coppersmith
Topics: Natural language processing (NLP), machine learning, social media mining

Brigham Young University
2011-2015
Group: Design Exploration Research Group
Mentor: Chris Mattson
Topics: Multi-objective optimization, design space exploration
Group: Design Exploration Research Group
Mentor: Chris Mattson
Topics: Multi-objective optimization, design space exploration

Air Force Research Laboratory
Summer 2011
Group: Turbine Engine Division
Mentor: John Clark
Topics: Evolutionary algorithms for optimization, turbine engine simulation
Group: Turbine Engine Division
Mentor: John Clark
Topics: Evolutionary algorithms for optimization, turbine engine simulation
Education
Stanford University
Brigham Young University
B.S. Mechanical Engineering, Mathematics Minor (Apr. 2015)
Advisor: Chris Mattson
Valedictorian, summa cum laude (GPA 4.00)
Advisor: Chris Mattson
Valedictorian, summa cum laude (GPA 4.00)
Past Projects

|
Meta GenAI Evaluations
I founded and led the centralized Evaluations org responsible for evaluation strategy, development, tooling, and execution for all GenAI foundation models (e.g. Llama).
Our work spans all modalities (text, image, audio, etc.), capabilities (reasoning, intelligence, agentic behaviors, safety, etc.), and evaluation types (human, automated, AI judges, etc.).
|
|
|
Snorkel AI
Building Snorkel AI, the Data Research Lab advancing frontier AI.
For more details on the company, visit snorkel.ai. For more details on my role at the company, visit my LinkedIn profile. |

|
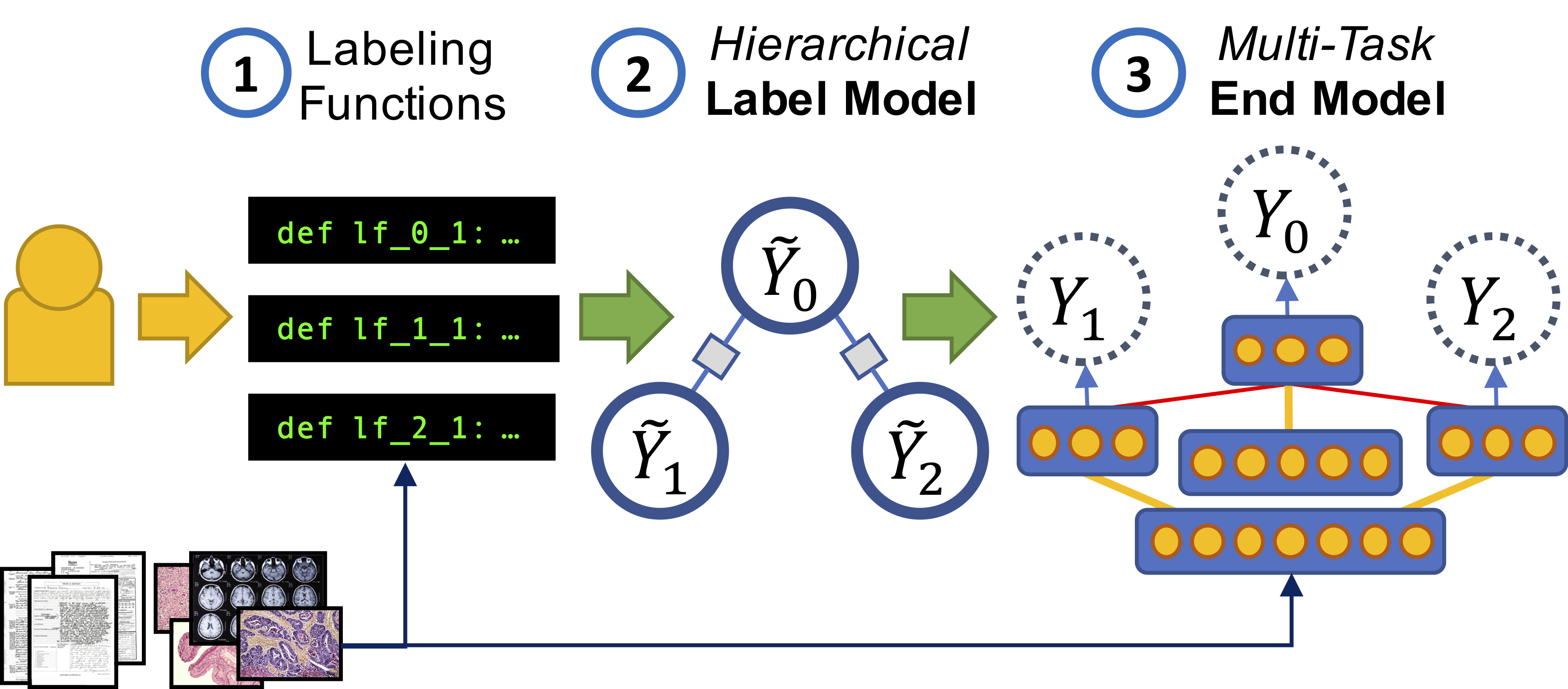
Snorkel: Research Library
Snorkel
is a system for rapidly creating, modeling, and
managing training data. It is the flagship implementation
of the data programming paradigm for supporting weak
supervision resources. Collaborators and active users
include over a forty major technical and medical organizations (e.g., Google, Microsoft, Intel, Toshiba, JPL, Alibaba, Stanford Medicine, etc.).
VLDB 2018 ("Best of VLDB")
|
|
Snorkel MeTaL: Weak Supervision
for Multi-Task Learning
We extend Snorkel to multi-tasking supervision and multi-task
learning (MTL). In particular, we are interested in the
massive multi-task learning regime where we
have large numbers of tasks and labels of varying types,
granularities, and label accuracies. Using Snorkel MeTaL,
we achieved new state-of-the-art scores on the GLUE Benchmark
and four of its component tasks.
AAAI 2019 (oral), DEEM (SIGMOD) 2018 (oral)
|
|
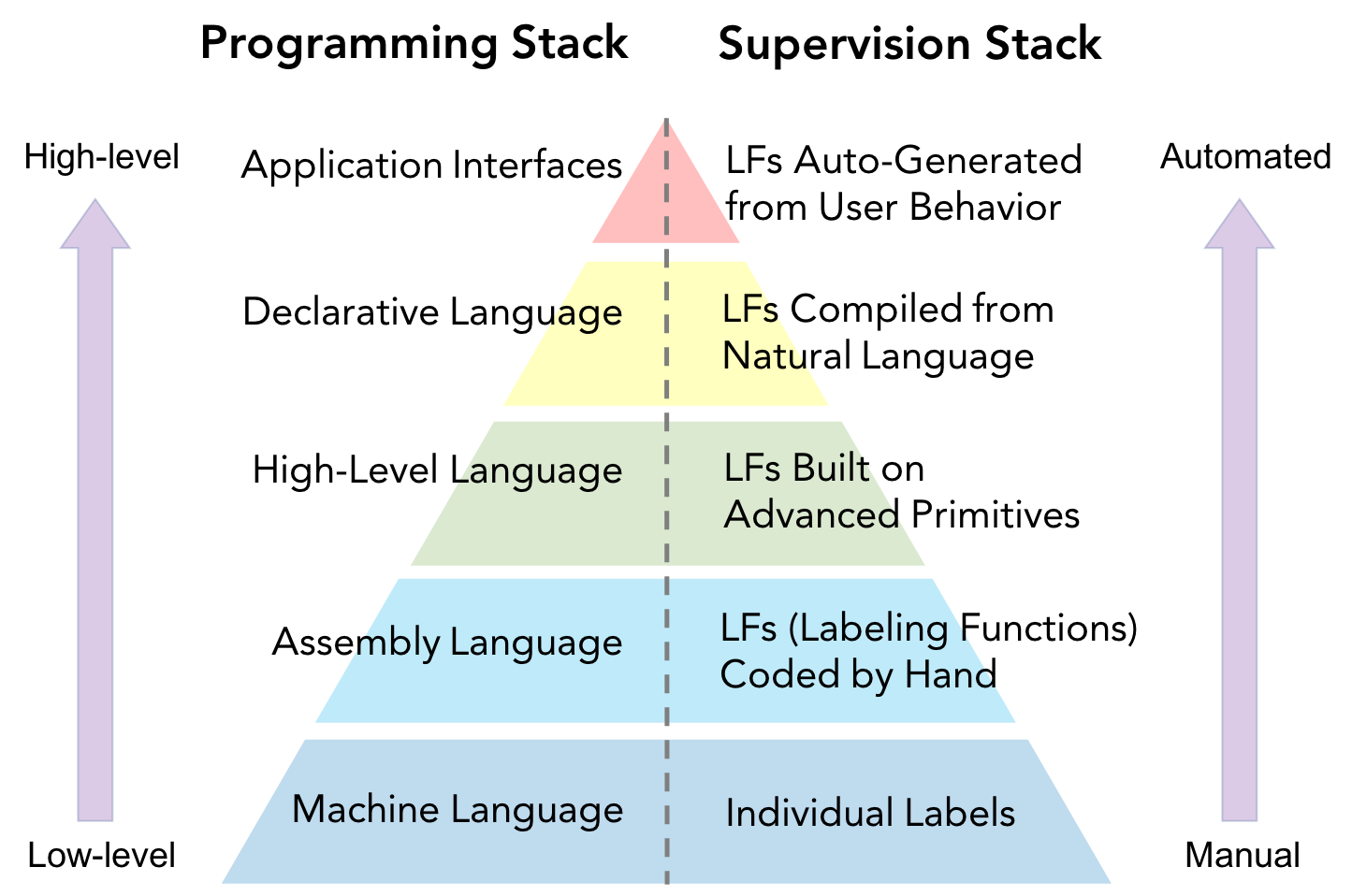
Software 2.0: Learning-Centric Software Stacks
Driven by accuracy improvements and deployment advantages, many organizations have begun to shift toward learning-centered
software stacks.
That is, "Software 1.0" code with explicit instructions written by programmers is being replaced by "Software 2.0" code that is written in the weights of neural networks.
In this paradigm, training data becomes the primary interface through which developers interact with their Software 2.0 systems.
This requires a new level of scalability, control, and efficiency when it comes to generating and shaping training sets.
We are exploring the ramifications of this new programming model and building the tools to support it.
CIDR 2019 (oral)
|
|
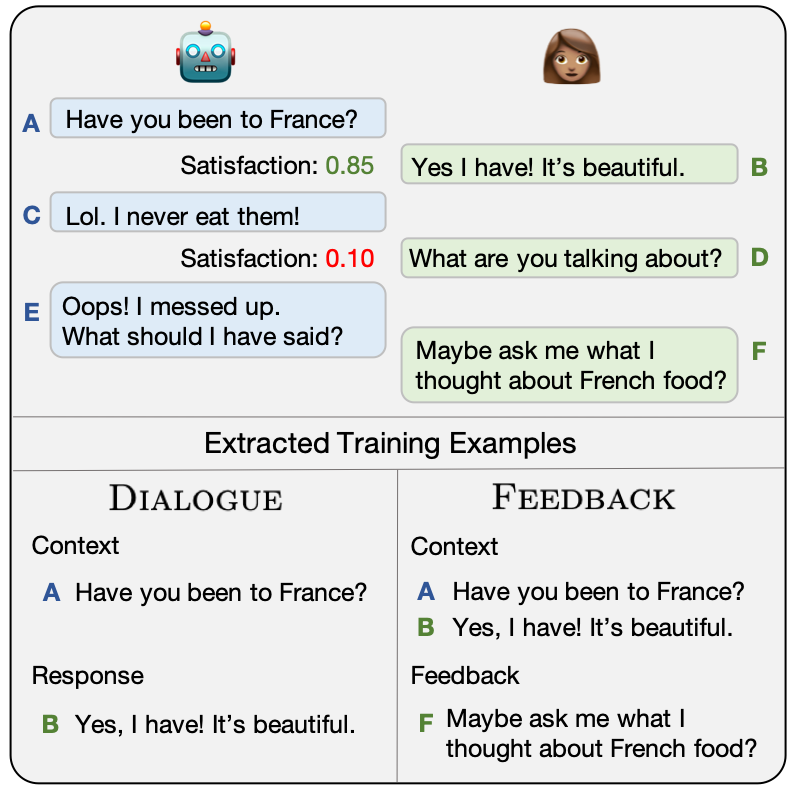
Self-Feeding Chatbots
Most of the conversations a chatbot sees over its lifetime happen after it's deployed.
These conversations aren't typically useable as training data, but give the chatbot the
right tools and it can learn from those too! We introduced a multi-task "self-feeding"
chatbot that knows how to extract new training examples from the conversations it
participates in to improve itself further after it's deployed.
ACL 2019
|
|
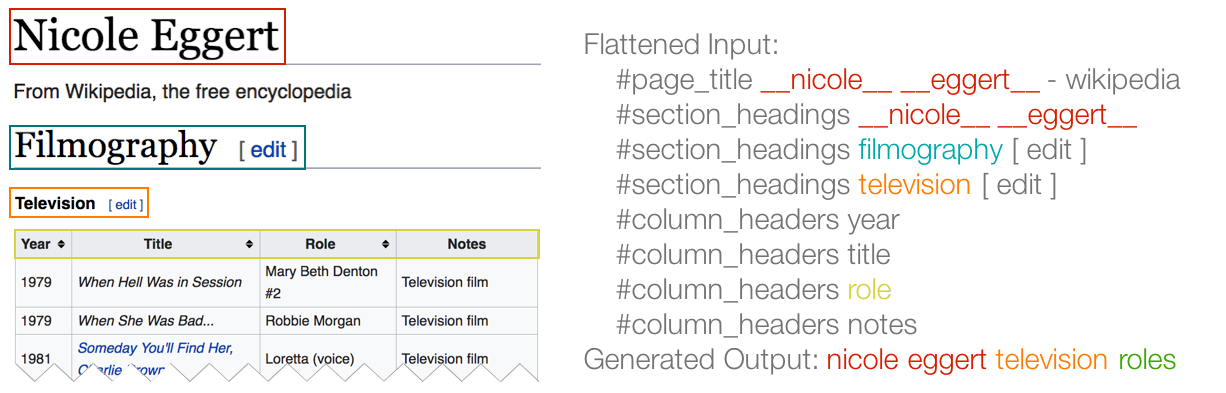
Generating Titles for Web Tables
We introduce a framework for generating titles for tables
that are displayed out of their original context. We use a
pointer-generator network, a sequence-to-sequence model that is
capable of both generating tokens and copying tokens from the
input (such as rare and out-of-vocab words), resulting in titles
that are both relevant and readable and reducing hallucinations.
The Web Conference (WWW) 2019
|
|
|
Babble Labble: Learning from Natural Language Explanations
We explore collecting natural language explanations
for why annotators give the labels they do and
parsing these into executable functions, which can then
be used to generate noisy labels for large amounts of
unlabeled data. The resulting probabalistically labeled
training dataset can then be used to train a powerful
downstream discriminative model for the task at hand.
We find that utilizing these natural language explanations
allows real-world users to train classifiers with
comparable F1 scores up to 100 times faster than when they
provide just labels.
ACL 2018 (oral), NeurIPS 2017 Demo
|

|
Fonduer: Knowledge Base Construction from Richly Formatted Data
We introduce an information extraction framework that utilizes
multiple representations of the data (structural, tabular,
visual, and textual) to achieve state-of-the-art performance
in four real-world extraction taks. Our framework is currently
in use commercially at Alibaba and with law enforcement agencies
fighting online human trafficking.
SIGMOD 2018 (oral)
|
|
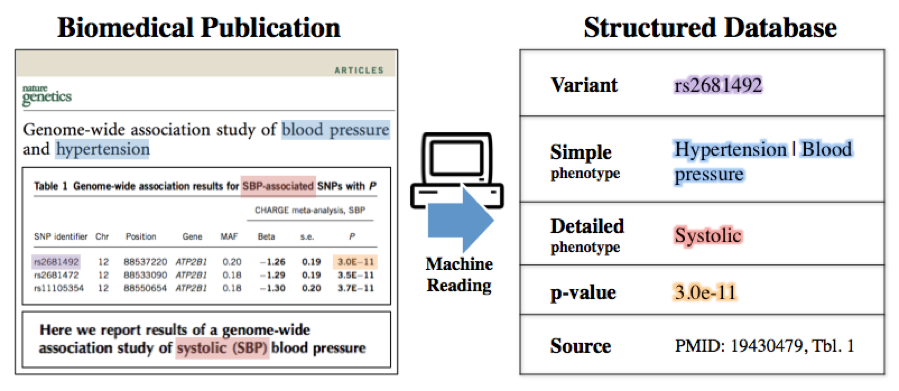
A Machine-Compiled Database of Genome-Wide Association Studies (Nature Comms)
Using the multi-modal parsing and extraction tools from Fonduer and learning and inference tools from
Snorkel, we construct a knowledge base of genotype/phenotype associations extracted from the text
and tables in ~600 open-access papers from PubMed Central. Our system expands existing manually
curated databases by approximately 20% with 92% precision.
Bio-Ontologies 2017, NeurIPS 2017 MLCB Workshop
[pdf]
|
|
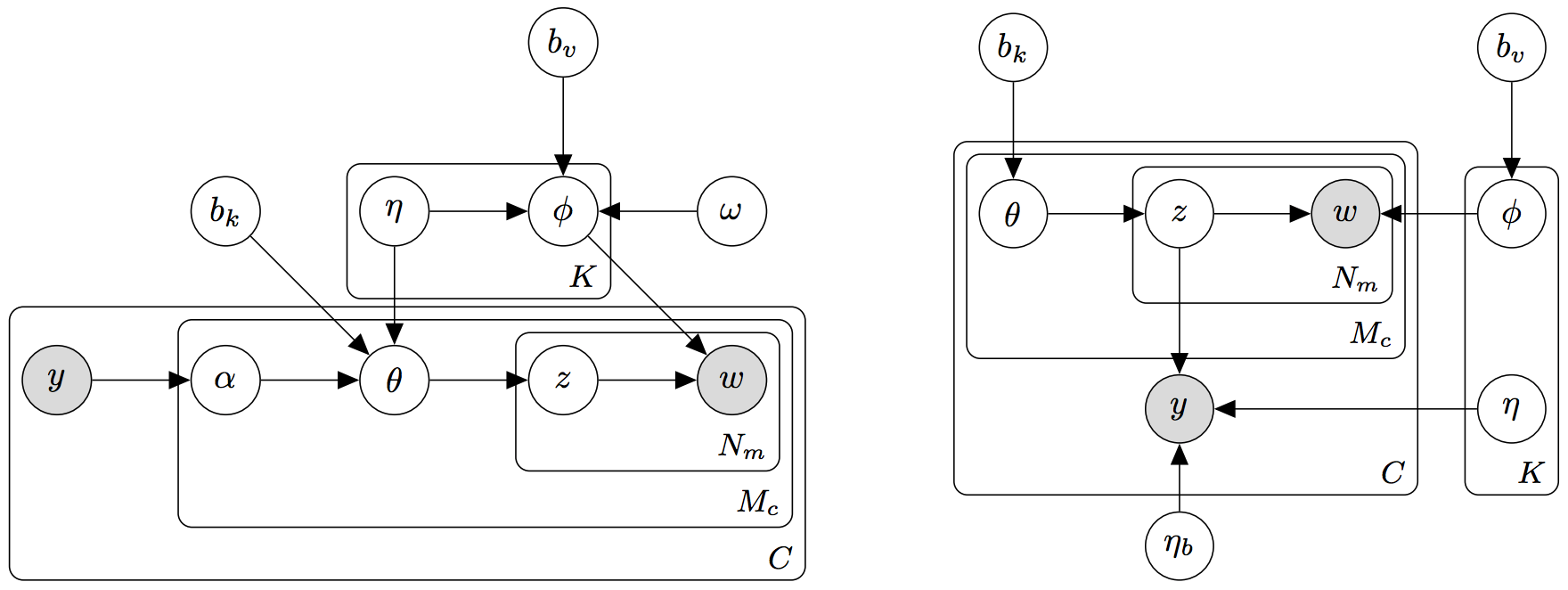
Collective Supervision of Topic Models for Predicting Surveys with Social Media
We use topic models to correlate social media messages
with survey outcomes and to provide an interpretable
representation of the data. Rather than rely on
fully unsupervised topic models, we use existing aggregated
survey data to inform the inferred topics, a class
of topic model supervision referred to as collective supervision.
AAAI 2016
|
|
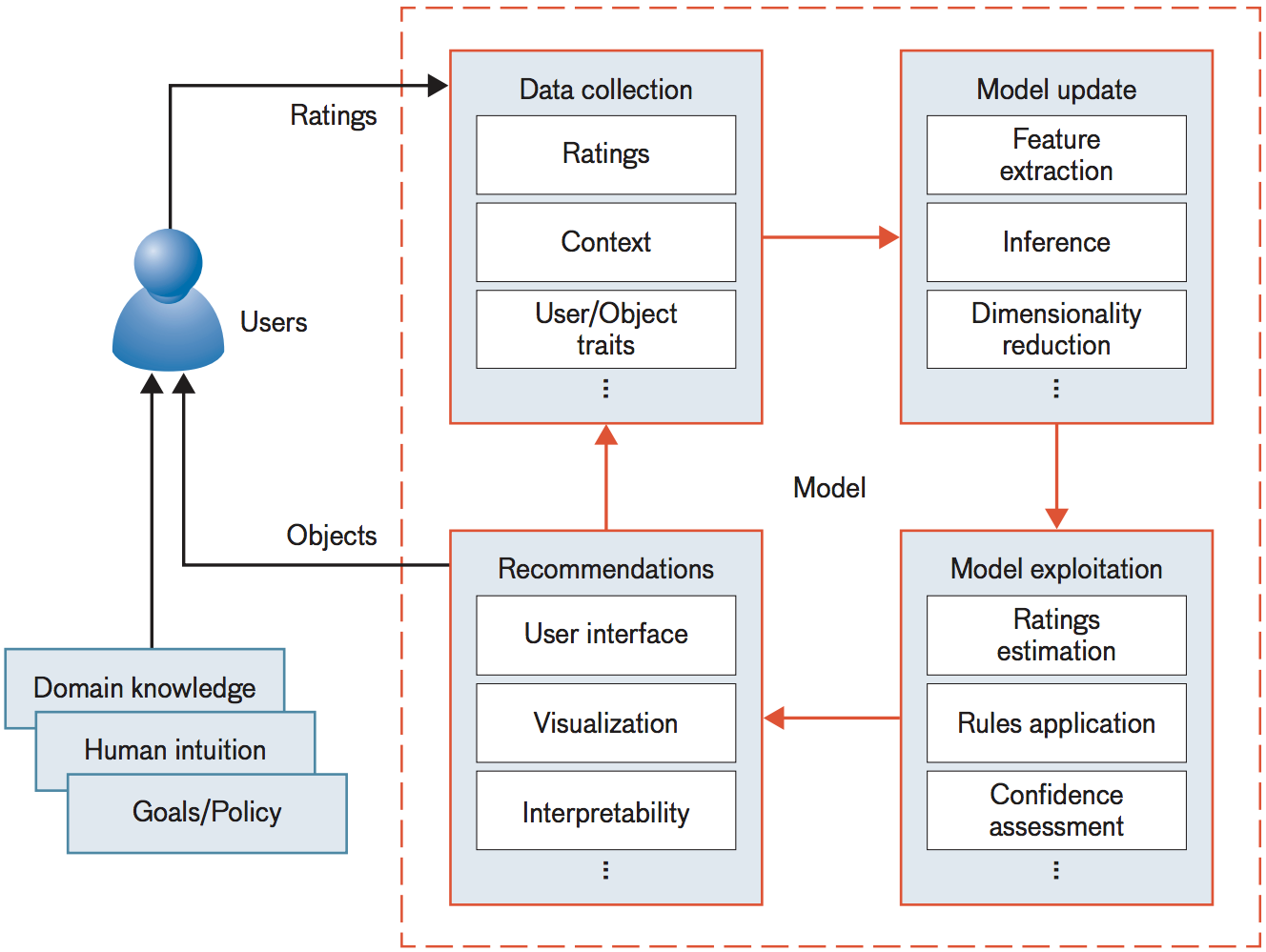
Recommender Systems for the Department of Defense and Intelligence Community
With an internal committee of 20 MIT and DoD researchers,
I spearheaded the construction of this report, which
formalizes the components and complexities of recommender systems
and surveys their existing and potential uses in the
Department of Defense and U.S. Intelligence community.
MITLL Journal 2016
[pdf]
|
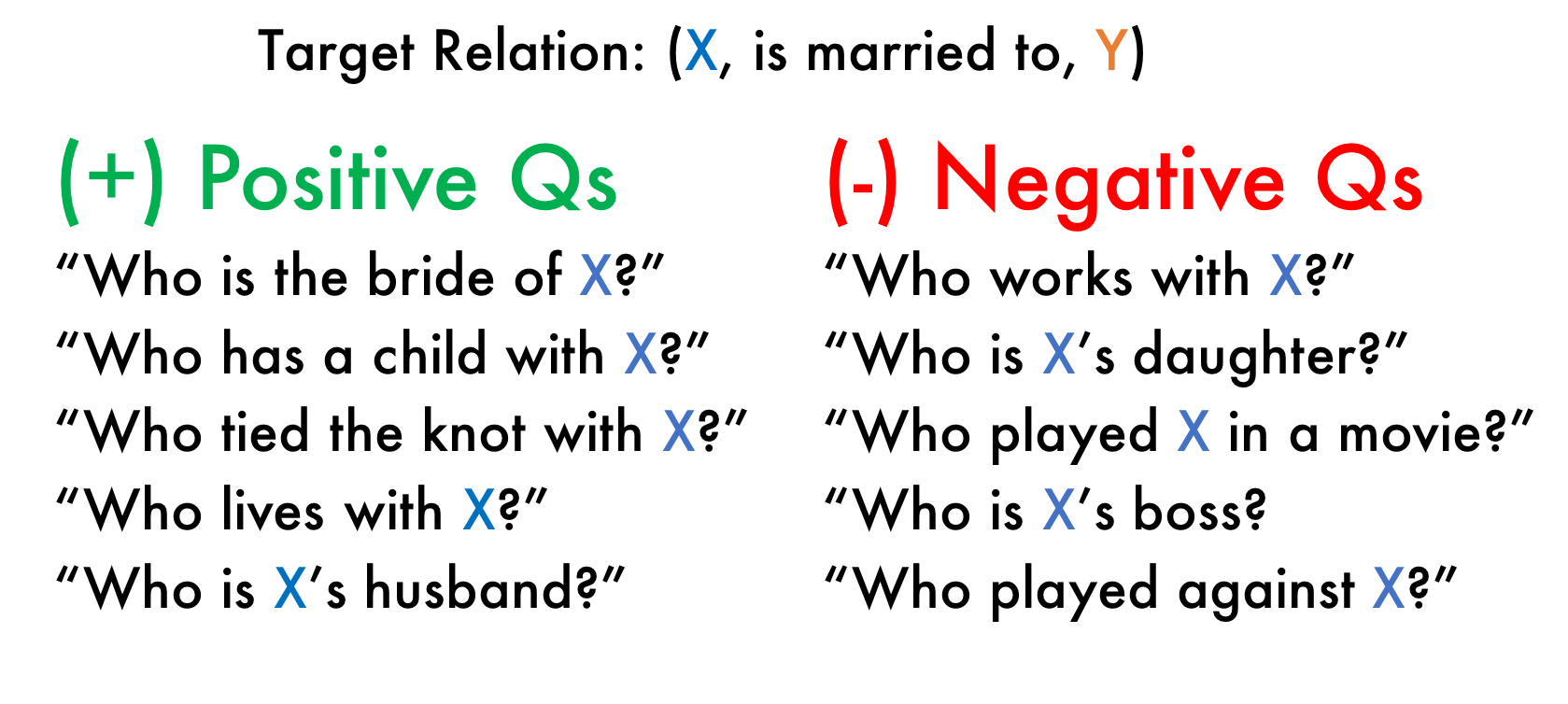
|
QALF: Information Extraction
for the Long Tail via Question Answering
We use a Question Answering (QA) model as a flexible means of
converting domain expertise expressed as natural language
into weak supervision resources (labeling functions, or LFs).
Preliminary results suggest that with as few as a dozen user inputs
(domain-relevant questions), we can quickly build first-order
extractors for new relations that lack distant supervision resources.
|
|
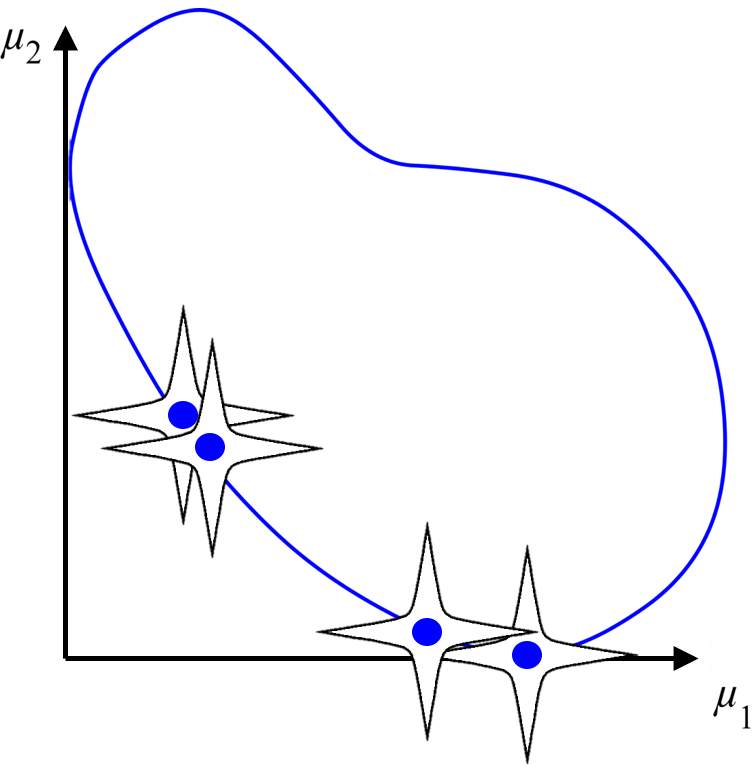
L-dominance: An approximate-domination mechanism for adaptive resolution of Pareto frontiers
We propose a mechanism called L-dominance (based on the
Lamé curve) which promotes adaptive resolution of solutions
on the Pareto frontier for evolutionary multi-objective
optimization algorithms.
SMO Journal, AIAA ASM 2015, Honors Thesis
Best Student Paper
|
|
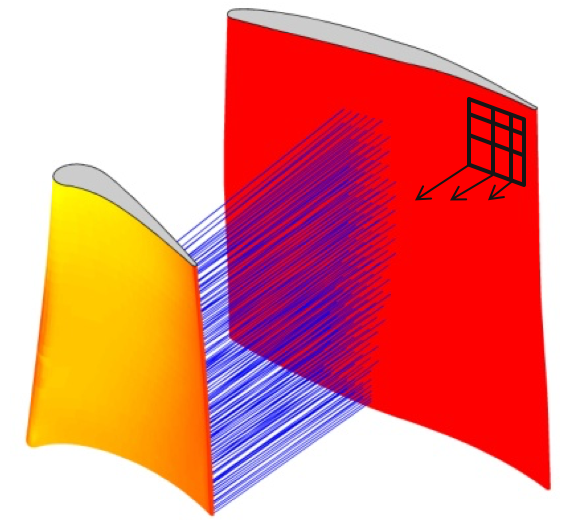
Reducing Shock Interactions in a High Pressure Turbine via 3D Aerodynamic Shaping
We show that the shock wave reflections inside a turbine
engine can be approximated by calculating the 3D surface
normal projections of the airfoils. Using a genetic algorithm,
we produce superior airfoil geometries (with respect to
high cycle fatigue failure) four orders of magnitude faster
than the traditional CFD-based approach.
AIAA Journal, AIAA ASM 2014
Best Student Paper
|
|
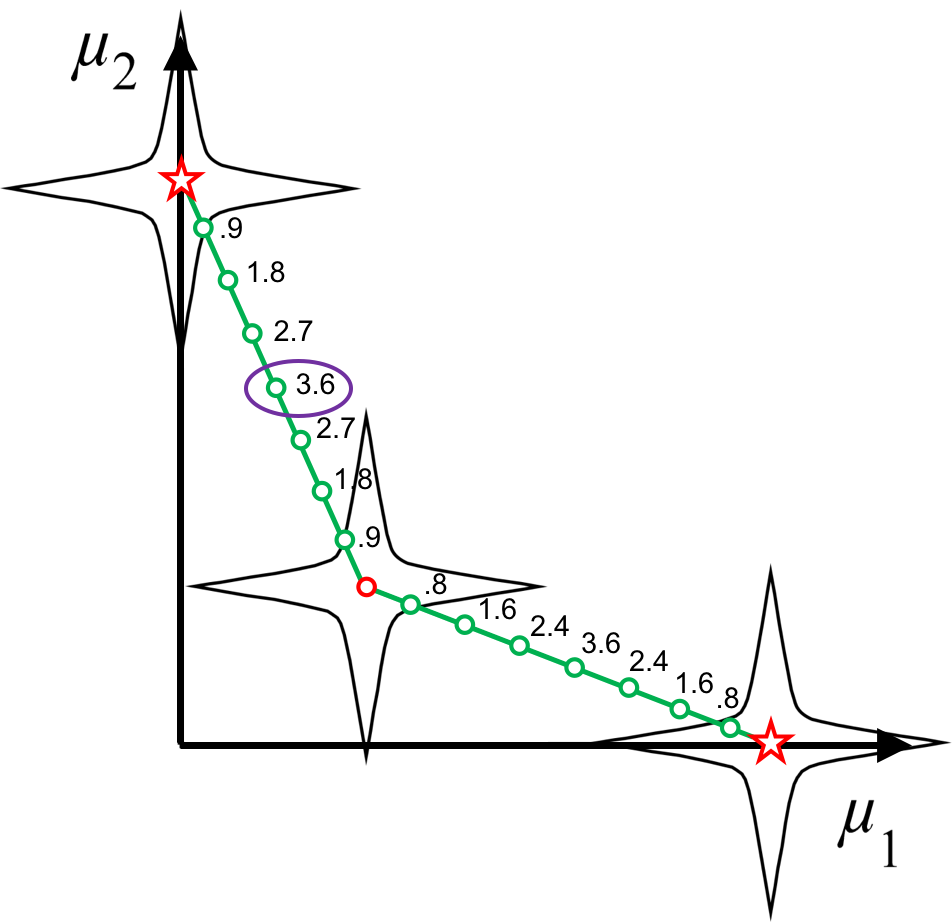
The Smart Normal Constraint Method for Directly Generating a Smart Pareto Set
We introduce the Smart Normal Constraint (SNC) method, the
first method capable of directly generating a smart Pareto
set (a Pareto set in which the density of solutions varies
such that regions of significant tradeoff have the greatest
resolution). This is accomplished by iteratively updating
an approximation of the design space geometry, which is
used to guide subsequent searches in the design space.
SMO Journal, AIAA MDO 2013
|
|
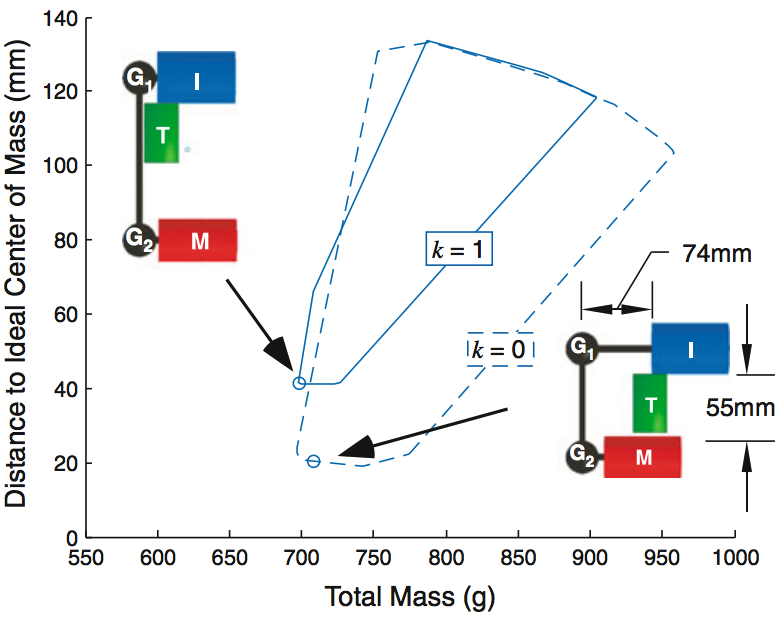
Usage Scenarios for Design Space Exploration with a Dynamic Multiobjective Optimization Formulation
We investigate three usage scenarios for formulation space
exploration, building on previous work that introduced a new
way to formulate multi-objective problems, allowing a designer
to change up update design objectives, constraints, and variables
in a fluid manner that promotes exploration.
RiED Journal, ASME DETC 2012
Best Paper
[pdf]
|